
Advanced AI Document Analysis
AI ChatPDF provides advanced analysis features with one-click document summaries and thorough examinations.
Superior Document Compatibility
Upload up to 20 documents at once, with a total of 5,000 pages. Enjoy no file size or upload limits, surpassing the capabilities of current chatpdf and even ChatGPT products.

Read and Ask Questions Simultaneously
Engage with original text and AI-driven queries for real-time interaction. Take notes and convert content into AI-enhanced writing seamlessly as you read.
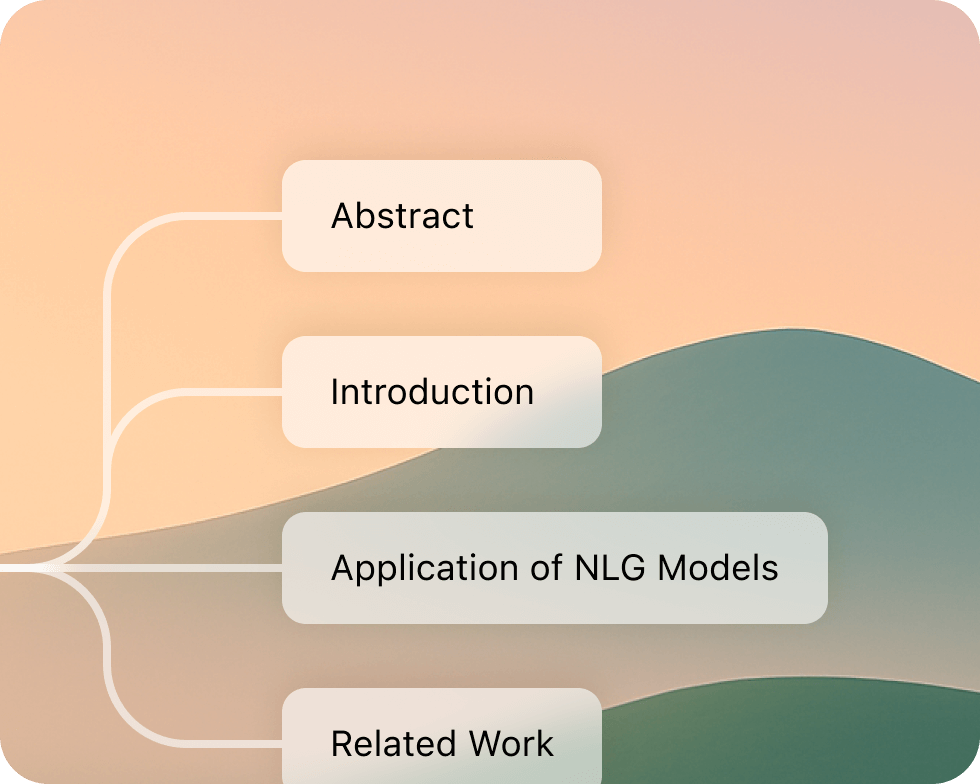
Mindmap Functionality
Instantly generate mindmaps from PDFs, facilitating quick comprehension and effective content visualization.

Convert PDFs to PPTs with one click
Effortlessly transform your PDFs into presentations with a single click.
Advanced Image and Chart Analysis
AI ChatPDF excels in interpreting charts and images with its "Capture & Ask" feature, allowing you to easily take screenshots and make inquiries for detailed and precise information extraction.
